Braintrust leads for production teams. CI/CD deployment blocking, zero-code gateway, managed infrastructure, 1 GB of free processed data.
Runner-ups:
- Arize: Open-source and SaaS options, but infrastructure expertise required
- Galileo AI - Packaged evaluators + runtime guardrails out of the box, but guardrails are Enterprise-only with a tiny 5k free tier
- Fiddler AI - Enterprise ML/LLM combo, but no free tier
- Helicone - Multi-provider proxy with cost tracking, but no evaluation
Pick Braintrust if you need automated deployment blocking. Pick others for open-source requirements or framework-specific needs.
Why teams look for Langfuse alternatives
Langfuse is a great self-hosted product. It serves solo developers prototyping locally and large enterprises running their own data centers. But when it comes to batteries included tools for optimizing your AI agents, many teams look for more robust products.
Most production teams fall between solo developers and enterprises requiring self-hosting. Hosted SaaS platforms eliminate infrastructure management, letting teams focus on building features instead of tuning databases. These platforms connect evaluation and production monitoring automatically, removing manual correlation work. They integrate directly into CI/CD pipelines with automated quality gates that block deployments when metrics fail, replacing manual log reviews with systematic regression prevention.
Production teams need managed platforms that run without infrastructure, enable collaborative evaluation, and automatically block bad code. This is the main reason teams explore Langfuse alternatives.
Top 5 Langfuse alternatives (2026)
1. Braintrust: Best LLM evaluation platform with CI/CD deployment blocking
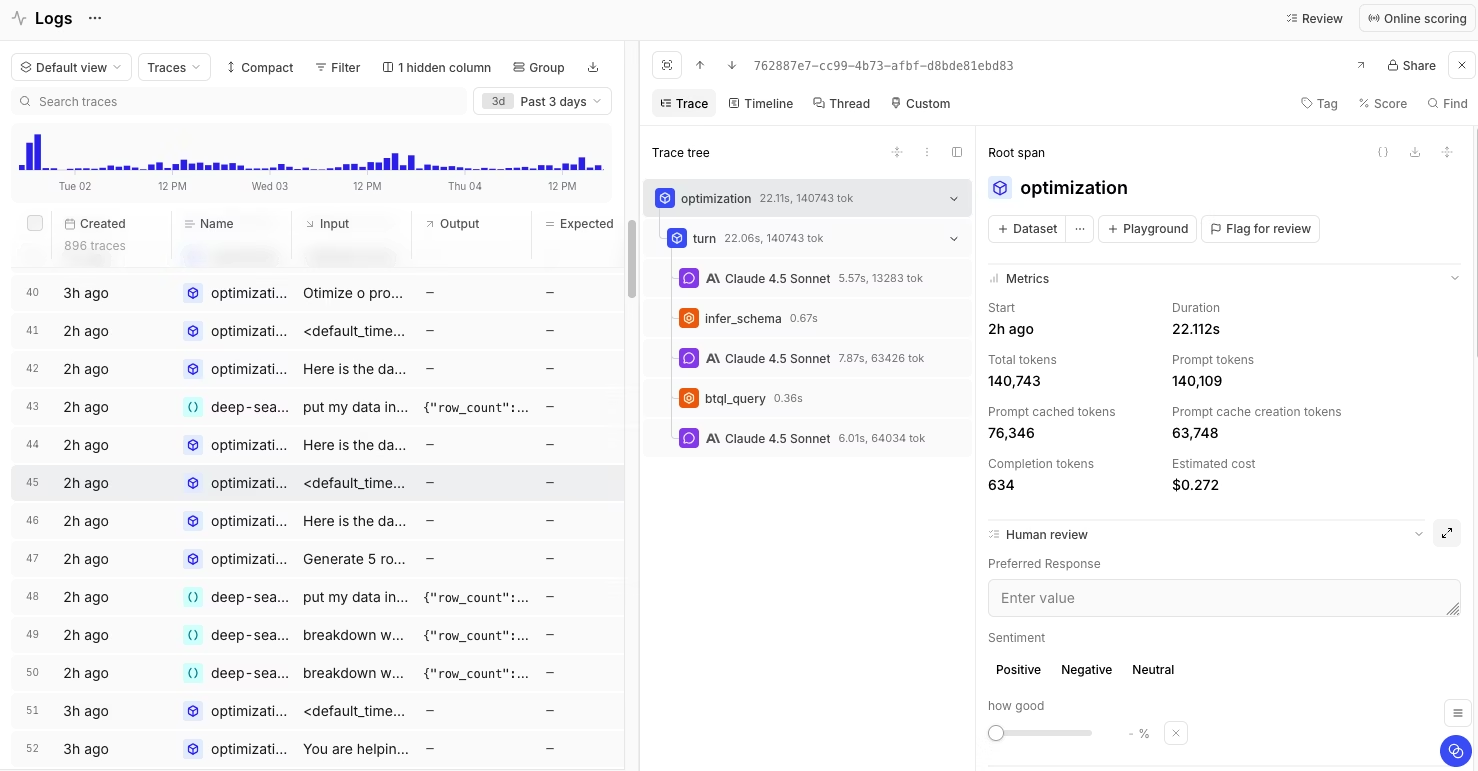
Braintrust catches quality issues during code review, not after deployment. When evaluation metrics fail in your CI/CD pipeline, Braintrust blocks the merge automatically. Making sure your team fixes the prompt before it ever reaches production.
Most teams juggle separate tools for experimentation, evaluation, and monitoring. Braintrust puts everything in one place. You test a prompt variation, run it through your evaluation suite, and see how similar patterns behaved in production, all without switching contexts. Production traces automatically become test cases, so failures you fix stay fixed.
The difference shows up in the daily workflow. Instead of exporting traces from one tool, running evals in another, then discussing results in Slack while tracking decisions in spreadsheets, your whole team works in the same interface. Engineers and product managers compare prompt outputs side-by-side and vote on which version ships.
Braintrust key features
- Custom scorers using Autoevals, hallucination detection, factuality checks, Loop AI auto-generates scorers, and statistical significance testing
- Run evaluations locally, in CI/CD pipelines, or on schedules with 10,000 free eval runs monthly
- SDK captures nested calls, AI gateway logs OpenAI/Anthropic/Cohere with zero code changes, 1 GB of free processed data monthly
- Trace views show retrieval context and reranking, link traces to dataset examples for debugging
- Topics runs a daily classification pass over every production trace, labeling it by task, sentiment, issues, and any custom facet you add, so recurring failure modes show up across all traffic instead of only the runs a scorer happens to catch
- Version control with rollback, A/B testing with traffic splitting, and an interactive playground across providers
- Import datasets from CSV/JSON/production logs, point-in-time versioning, and team annotation workflows
- GitHub Actions and GitLab CI integration, PR comments with pass/fail status, quality gates block merges
- Cloud-hosted with SOC 2 or self-hosted (Enterprise), multi-provider support
Pros
- Automatic merge blocking when quality drops. Langfuse requires manual review before merging changes.
- No infrastructure to manage. Langfuse self-hosting needs PostgreSQL, ClickHouse, Redis, and Kubernetes.
- Evaluation automatically links to production traces. Langfuse runs experiments separately from live monitoring.
- Observability that surfaces problems on its own. Topics classifies your logs in the background and ranks which issues recur, so you act on the handful of patterns that matter rather than reading traces by hand the way Langfuse expects.
- Larger free tier. 1 GB of processed data and unlimited users versus 50K units for two users on Langfuse Cloud.
- 30-minute setup. Langfuse production deployment requires significant time.
Cons
- Self-hosting is available only on the Enterprise tier
- Closed-source, unlike Langfuse's MIT license
Pricing
Free tier includes 1 GB of processed data per month, unlimited users, and 10,000 evaluation runs. Pro plan starts at $249/month. Custom enterprise plans available.
Best for
Teams building production LLM applications who need CI/CD deployment blocking, automated evaluation workflows, collaborative prompt experimentation, and integrated observability without framework lock-in.
Why teams choose Braintrust over Langfuse
| Feature | Braintrust | Langfuse |
|---|---|---|
| Deployment blocking | Automatic merge prevention on failures | Manual review required |
| Infrastructure | Fully managed platform | Self-host PostgreSQL, ClickHouse, Redis, S3 |
| AI gateway | Zero-code traffic capture | SDK in all services |
| Eval-trace integration | Automatic linking | Manual correlation |
| Production setup | 30 minutes | Kubernetes deployment |
| Scorer generation | AI-powered | Manual creation |
| Failure-mode discovery | Topics classifies all traffic daily | Manual log review |
| Free tier | 1 GB data/month, unlimited users | 50K units/month, two users |
Engineering teams at Perplexity, Airtable, and Replit use Braintrust's automated blocking to stop prompt regressions during pull request reviews rather than debugging customer-reported issues post-deployment. Start with Braintrust's free tier →
2. Arize: Open-source and enterprise LLM observability
Arize offers Phoenix (open-source) and Arize AX (SaaS). Phoenix provides self-hosted LLM observability with no licensing costs. Arize AX adds enterprise support and traditional ML monitoring capabilities.
Pros
- Open-source option with free self-hosting
- Framework integrations for LlamaIndex, LangChain, DSPy applications
- Dataset versioning and experiment tracking
- Agent graph visualization for multi-step workflows
Cons
- Self-hosting Phoenix requires Docker and Kubernetes expertise similar to Langfuse
- No automatic deployment blocking in CI/CD pipelines
- Evaluation workflows need custom scripts
- Every service requires SDK instrumentation, no zero-code gateway
- Free tier limits to 25K spans and 1 user, compared to Braintrust's 1 GB of processed data for unlimited users
Pricing
Free for open-source self-hosting. Managed cloud at $50/month. Custom enterprise pricing.
Best for
Teams managing self-hosted services on Docker or Kubernetes who want open-source LLM observability.
Read our guide on Arize Phoenix vs. Braintrust.
3. Galileo AI: Vendor-managed evaluations for teams who don't want to build their own
Galileo is a managed, opinionated evaluation stack that makes most of the hard decisions for you. You don't configure your own scorers, you can't self-host unless you're on Enterprise, and you don't assemble a pipeline from scratch. That cuts both ways. Teams in regulated or high-risk environments get a production-ready system quickly, while teams that need open-source transparency, deployment control, or custom scorer logic will run into limits fast.
Pros
- 20+ vendor-maintained evaluators (hallucination detection, context adherence, completeness) that work out of the box, with no scorer configuration required
- Luna-2 small language models for low-latency inline scoring without routing through a heavyweight LLM
- Runtime guardrails intercept unsafe or off-policy responses before they reach end users
- Galileo Insights flags failure modes and runs root-cause analysis across evaluation runs, which cuts down manual triage
- Integrations for CrewAI, LangGraph, OpenAI Agent SDK, LlamaIndex, Strands, and OTEL
Cons
- Closed, proprietary platform. There's no open-source codebase to audit, fork, or extend, so teams that require full code transparency are stuck
- Runtime guardrails are locked behind the Enterprise tier, so one of its main selling points is out of reach on lower plans
- No native CI/CD deployment blocking, so evaluation results don't gate releases unless you build a workaround
- The free tier caps at 5,000 traces per month, which gets tight during active development
- Self-hosting is Enterprise-only, so teams that need on-premises or VPC deployment have no option below that tier
Pricing
Galileo offers a Free tier capped at 5,000 traces per month. The Pro plan runs $100/month and includes 50,000 traces with usage-based overages. Enterprise pricing is custom and required to unlock both runtime guardrails and self-hosting.
Best for
Teams in regulated or high-risk verticals like healthcare, finance, and legal that want a ready-made evaluation stack with inline guardrails and are comfortable on a managed, vendor-controlled platform.
Read our guide on Galileo AI vs. Braintrust.
4. Fiddler AI: Enterprise ML and LLM monitoring platform
Fiddler AI built its platform for classical machine learning monitoring, then extended capabilities into generative AI observability. The product targets enterprises running both traditional ML models and LLM applications that want unified monitoring.
Pros
- Monitors traditional ML models and LLM applications in one dashboard
- Embedding drift detection tracks distribution shifts in real-time
- Built-in hallucination detection with configurable safety rules
- Root cause analysis surfaces performance degradation sources
- Threshold-based alerting for quality metrics
Cons
- Interface design originates from tabular ML workflows, making generative AI patterns less natural
- Monitoring and alerting happen after deployment, with no automatic quality gates in CI/CD
- Enterprise-only sales process without free tier or self-service trial access
- Traffic capture requires SDK instrumentation, with no zero-code proxy option
- Prompt iteration happens outside the platform, with no version control or A/B testing built in
Pricing
Custom enterprise pricing only.
Best for
Enterprises currently using Fiddler for classical ML model monitoring that need to extend the same platform to cover LLM applications with unified drift detection and explainability across both model types.
5. Helicone: Multi-provider proxy with cost tracking
Helicone operates as a unified API gateway supporting LLM providers like OpenAI, Anthropic, Google, Cohere, and other providers. The platform provides automatic request logging with a focus on cost tracking and usage analytics.
Pros
- Single gateway supports multiple LLM providers
- Endpoint change enables logging without application code modifications
- Cost breakdowns show spending per user, project, or provider
Cons
- Zero evaluation capabilities, no scoring, no test suites, no quality analysis
- No tools for dataset creation and prompt comparison
- Request logging only, missing nested trace analysis and agent debugging capabilities
- Unlike Braintrust, no automatic deployment blocking in CI/CD pipelines
Pricing
Free tier (10K requests per month). Paid plan starts at $79/month.
Best for
Companies using multiple LLM providers who need unified request logging and per-provider cost tracking through one gateway without evaluation workflows.
Read our guide on Helicone vs. Braintrust.
Langfuse alternative feature comparison
| Feature | Braintrust | Arize Phoenix | Galileo AI | Fiddler AI | Helicone |
|---|---|---|---|---|---|
| Distributed tracing | ✅ | ✅ | ✅ | ✅ | ✅ |
| Evaluation framework | ✅ Native | ✅ Templates | ✅ | Partial | ❌ |
| CI/CD integration | ✅ | ✅ Guides | Partial | ❌ | ❌ |
| Deployment blocking | ✅ | ❌ | ❌ | ❌ | ❌ |
| Proxy mode | ✅ | ❌ | ❌ | ❌ | ✅ |
| Open source | ❌ | ✅ Full | ❌ | ❌ | ✅ |
| Self-hosting | ✅ | ✅ Phoenix only | ✅ | ✅ | ✅ |
| Multi-provider | ✅ | ✅ | ✅ | ✅ | ✅ |
| Experiment comparison | ✅ | ✅ | ✅ | Basic | ❌ |
| Custom scorers | ✅ | ✅ | ✅ | ✅ | ❌ |
| A/B testing | ✅ | ❌ | Partial | ❌ | ❌ |
| Agent visualization | ✅ | ✅ Graphs | ✅ | ❌ | ❌ |
| SaaS free tier | ✅ 1 GB processed data, unlimited users | ✅ 25K trace spans, one user | ✅ 5K traces | ❌ | ✅ 10K requests |
Choosing the right Langfuse alternative
Choose Braintrust if: You ship LLM features daily and cannot afford prompt regressions reaching production. Automated deployment blocking, zero-code observability, and managed infrastructure mean your team moves faster while your competitors debug customer-reported issues.
Choose Arize Phoenix if: Full open-source code access is non-negotiable, you have platform engineering resources for PostgreSQL and Kubernetes management, or OpenTelemetry standards matter for your stack.
Choose Galileo AI if: prebuilt evaluators accelerate your evaluation setup, inline runtime guardrails are a hard requirement, and your team operates in a regulated or high-risk environment at Enterprise scale.
Choose Fiddler AI if: Your organization already pays for Fiddler to monitor classical ML models and wants one platform covering both traditional and generative AI with enterprise support contracts.
Choose Helicone if: OpenAI is your only model provider, straightforward cost tracking covers your observability needs, or you want the simplest possible proxy setup without evaluation features.
Why Braintrust is the best Langfuse alternative
Langfuse gives you infrastructure control. Braintrust gives you time back.
The difference matters when you're shipping code daily. Langfuse requires someone on your team who understands database performance, Kubernetes scaling, and orchestration of the evaluation pipeline. That person exists at some companies. At others, that expertise doesn't exist or costs more than a managed platform.
Braintrust changes the equation by preventing problems instead of reporting them. Your CI/CD pipeline runs evaluations and blocks the merge when quality drops. No manual review, no missed regressions, no customer complaints about prompts that should never have shipped. The platform handles infrastructure, proxy logging works without code changes, and production traces feed your test suites automatically.
Companies like Perplexity, Notion, Stripe, and Zapier use Braintrust for preventing deployment issues that matter more than owning the database layer.
Get started free or schedule a demo to see observability and evaluation working together without infrastructure requirements.
Frequently asked questions
What is the main difference between Langfuse and Braintrust?
Langfuse is open-source with free self-hosting but requires maintaining PostgreSQL, ClickHouse, Redis, and S3 infrastructure, plus Kubernetes for production scale. Braintrust provides a managed platform with zero infrastructure overhead and automatic CI/CD deployment blocking.
Which platform has better evaluation automation?
Braintrust delivers complete evaluation automation with deployment blocking built in. CI/CD pipelines execute scorers automatically, analyze statistical significance, and block merges when quality degrades. Langfuse provides LLM-as-a-Judge evaluations and custom scorer primitives, but teams assemble the orchestration layer themselves for comprehensive regression testing. Braintrust packages this automation ready to use immediately.
Which Langfuse alternative works best for teams that need runtime guardrails?
Galileo AI is the strongest choice for teams that require inline, real-time guardrails. Galileo's runtime guardrails intercept and block harmful or out-of-policy outputs at inference time, which is built for regulated and high-risk environments. The catch is access. Guardrails sit behind the Enterprise plan, and the free tier caps out at 5,000 traces, so it's hard to evaluate at scale before you commit. Braintrust handles guardrails differently. Deployment blocking in CI/CD pipelines stops regressions before they reach production, and the AI gateway adds a managed infrastructure layer for request-level control. With a free tier that covers 1 GB of processed data and framework-agnostic SDKs, Braintrust covers the full path from evaluation to deployment without an Enterprise contract. Choose Galileo AI when inline blocking at runtime is non-negotiable. Choose Braintrust if you want guardrail-style safety as part of a broader evaluation and observability workflow.